
Using ColdFusion's CFDBInfo to Dynamically Output Database Columns and Tables
The ColdFusion tag CFDBInfo was introduced in ColdFusion 8. I finally got around to playing with it and thought someone other than me might find this useful.
<!--- this dsn is used throughout the examples --->
<cfset REQUEST.dsn="cfartgallery" />
<!--- databases --->
<h4>DATABASES</h4>
<cfdbinfo datasource="#REQUEST.dsn#" name="getDBs" type="dbnames" />
<cfdump var="#getDBs#" />
This should return something similar to:
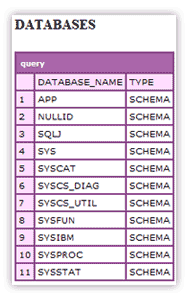
List all tables associated with the dsn:
<!--- tables --->
<h4>ALL TABLES</h4>
<cfdbinfo datasource="#REQUEST.dsn#" name="getTables" type="tables" />
<cfdump var="#getTables#" />
You should now see something similar to:
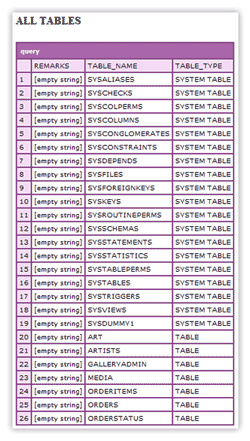
As you can see, you might not want all tables returned. So, unless you want or need information on all of the system tables, you could use something like this:
<h4>NON SYSTEM TABLES</h4>
<!--- using query of query to scrap any sys tables --->
<cfquery name="getNonSysTables" dbtype="query">
SELECT REMARKS, TABLE_NAME, TABLE_TYPE
FROM getTables
WHERE TABLE_TYPE <> 'SYSTEM TABLE'
</cfquery>
<cfdump var="#getNonSysTables#" />
Now you should see this:
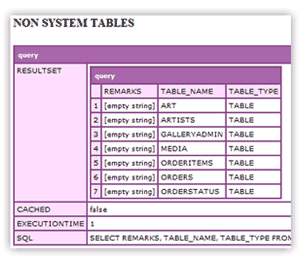
Dynamically generate all tables along with its detailed information:
<!--- columns --->
<h4>ALL TABLES: DETAILS</h4>
<hr size="1" />
<cfoutput query="getTables">
<h4>#getTables.TABLE_NAME#</h4>
<cfdbinfo datasource="#REQUEST.dsn#" name="getColumns" type="columns" table="#getTables.TABLE_NAME#" />
<cfdump var="#getColumns#" />
</cfoutput>
This begins to generate a long list of tables and the info:
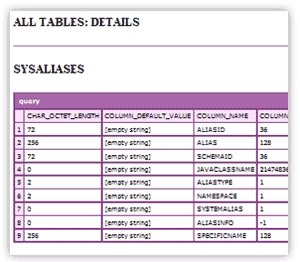
Once again, maybe you don't want all tables. If that's the case, then you could use a method similar to the following to ignore system tables:
<h4>NON-SYS TABLES: DETAILS (Using CFIF on getTables query)</h4>
<hr size="1" />
<cfoutput query="getTables">
<!--- scrap the system tables --->
<cfif left(getTables.TABLE_NAME, 3) NEQ 'SYS'>
<h4>#getTables.TABLE_NAME#</h4>
<cfdbinfo datasource="#REQUEST.dsn#" name="getColumns" type="columns" table="#getTables.TABLE_NAME#" />
<cfdump var="#getColumns#" />
</cfif>
</cfoutput>
Here you'll see only non-system tables and their related information:
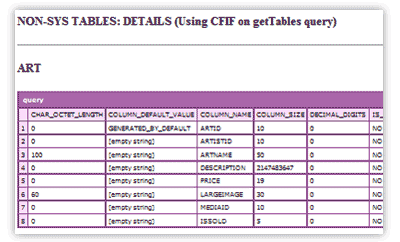
And yet, another method to list non-system related tables:
<h4>NON-SYS TABLES: DETAILS (Using output of Query of Query - getNonSysTables)</h4>
<hr size="1" />
<cfoutput query="getNonSysTables">
<h4>#getNonSysTables.TABLE_NAME#</h4>
<cfdbinfo datasource="#REQUEST.dsn#" name="getColumns" type="columns" table="#getNonSysTables.TABLE_NAME#" />
<cfdump var="#getColumns#" />
</cfoutput>
As you can see, CFDBInfo is quite a powerful little tag which can return a ton of useful information. Hope it helps you in your next project. Enjoy!

Comments
On of the things I do not like about cfdbinfo is too slow to run in production. But since most of the metadata about a DB does not change, you got me thinking, would it make sense to run the cfdbinfo queries in onApplicationStart() and store the results in the Application Scope. Then run the Query-of-Queries against the cached results.
I think this would greatly improve performance if you were to use these things in production. What do you think?
I suppose it would depend on how you would want to use the information. As you pointed out, once a database has been created, the general structure _usually_ doesn't change much (unless you're creating tables on the fly, etc.). Another point you made is true, I noticed how sluggish ColdFusion seems when running some of these "queries."
I used some of the similar methods to quickly obtain info on a db that I didn't have access to otherwise (i.e., using SQL Server Management Studio or MySQL Admin, etc.). I wasn't necessarily using the code in a production app, but needed the information to see the db structure (tables, keys, relationships ...). CFDBInfo worked like a charm in this case.
So, I guess the roundabout answer to your question is I'm not sure if I would use it in a production app specifically. I would have to think more about exactly _how_ to use it in that way. The only thing I would have (at this point anyway) about storing it in the Application scope would be possible security issues. If you don't recommend storing things like your DSN in your App scope, then I probably wouldn't want to keep a complete schema of my db in there either. I'll have to think about this a bit more.
Nevertheless, I sure am glad to have CFDBInfo in my CFToolbox.
Something else I thought of though and I'm not exactly sure if this would work per se, but ...
What if you could use the information obtained in the CFDBInfo query, and then dynamically create an XML file which contains all of the tables and their relationships? Also, how could something like this help someone using ORM (i.e., Transfer, DataFaucet, etc.)?
Ahh, ok. Yeah, that makes perfect sense. Pretty cool actually. Now, who's gonna build it? ;-)
I'm pretty certain actually that I was the person who submitted the ER that resulted in CFDBInfo during the CF8 alpha. Of course I wasn't the first person to use metadata with CF. Even on CF5, Claude Schneegans had published an ODBC-based CFX tag for getting meta data. I'd been doing some metadata stuff *without* ODBC on CF5 that was really cryptic and slow because it relied on doing something different to get the metadata for each type of db. And then once MX had been released it became a lot easier. I was ecstatic when I was finally able to use JDBC and the technique became semi-consistent. But you still have to watch out for inconsistencies because different databases still return non-standard data, like MS SQL Server returns "int identity" as the data type for a column, which is non-standard.
I think I also wrote the first major article on the use of metadata for CFDJ shortly after that and it's interesting because that was my first article and because it almost didn't happen. The editor felt the original proposal was too advanced for their readers and then later someone else recommended I resubmit and I think put in a recommendation for me and it got accepted. At the time the article ended up with a short glossary of OO terms that you generally wouldn't find in any recent articles for ColdFusion. How the community has changed! :)
But that's enough history (and ego stroking). :) With regard to DataFaucet, metadata is still gathered via JDBC directly rather than through CFDBInfo. I feel a little guilty honestly because I was going through a rough time in 2006 and basically dropped out of the alpha about the time the tag was added, without testing it. And it wasn't until much later that I got around to looking at it and realized that it wasn't realy compatible with the tools I'd already built. I do want at some point to have a version of DataFaucet that uses CFDBInfo so that it will work across all the CFML engines once they all implement the tag. But up to this point that hasn't managed to get up to the top of my to do list.
With regard to caching metadata, yes DataFaucet does. It doesn't write any XML files, it just caches it in memory. I don't think table names are cached, because that method isn't used with enough frequency to be problematic. What does get cached are the column definitions and primary and foreign key constraint information (the latter being the biggest problem with converting for me).
@Jason - personally I don't like the idea of loading the metadata onApplicationStart, simply because it could be a lot of data and the odds are you're not going to need all of it on whatever page initializes the application (and of course, you never know what page people will enter on, so you don't know what page will start the app). I much prefer a "lazy loading" system, where the app just loads up a metadata object onApplicationStart and then as data for different tables become needed it then performs the fetch and cashes it for the next time, the same way IoC frameworks like ColdSpring work for example.
And actually I just recently managed to get the same sort of lazy-loading thing to work for my function libraries in the latest version of the onTap framework, which has significantly improved performance on CF8. But not on CF7 because the lazy-loading libraries only work with onMissingMethod. :) But none the less I've been pretty happy about being able to finally get the libraries to load on-demand the way I always wanted them to. :)
I will say that the DataFaucet ORM strategy tends to be a bit different than other ORMs. The traditional philosophy is to start with an object model and deliberately force yourself to not think about any kind of data structure and then later make the database match your object model. And there's not necessarily anything wrong with that approach, although I disagree with the OO purists who say that all forms of thought that are not OO are obviously inferior in every way across all use cases to OO theory and therefore should never be allowed. I just don't find that kind of arbitrary rigidness to be a practical or useful ideology. DataFaucet will actually go both directions. You can choose to model the db off of your objects (and the ORM will even create tables for you), or you can go the other direction if you happen to already have a database (which as Brian Rinaldi pointed out after our CFUG meeting the other day is often the request from your employer), and then model the objects to populate the database.
I just released a scaffolding tool for the onTap framework last week or so that generates CFCs and views from your database schema (something PLUM also does). I probably won't be using the scaffolding tool myself, not because it creates bad code, but because I personally find it easier to just write the files out myself. I will however maintain it and add features if people request them. :)
But getting back to the comments about metadata ('cause I'm getting off-track again), my understanding of Transfer is that it's based on that notion of always starting with business objects and then creating a database schema to support that model, although it doesn't create tables (at least currently). And so when you use Transfer, you've got to create your database and then create an XML config file for Transfer separately that shows how each column in the database maps to each property in your business objects. And if you wanted to speed that up I suppose you could use CFDBInfo as the engine for a code generator that would generate your Transfer config. Though many OO purists would likely say that defeats the purpose of using an ORM tool like Transfer, because that means you're using non-OO thought (a relational db schema) to generate your objects. (See, there is a method to my madness.) :)
First, thank you for submitting the enhancement request for CFDBInfo way back when. It's certainly a most useful tool. Especially, as I indicated earlier, when you need/want to know facts about a preexisting database that can't be accessed (for whatever reason) in the typical ways.
Secondly, thanks also for all of the other information. I've only recently begun to look at ORMs and DataFaucet definitely looks impressive. Having spent so much time learning and working with SQL, I guess it's just difficult to "give up" some of the tasks I enjoy doing ... such as building databases, writing the queries, etc. I can definitely see the value in using DataFaucet, and I should really spend some time to learn more about it.
You can copy the comment into the DataFaucet blog if you want, but I think it's definitely pertinent and useful here as well.
I also know very little about Transfer, but if it has an XML config file, then I agree that CFDBInfo (or it's underlying java methods) could be used to dynamically generate it.
I also want to learn more about Hibernate (http://www.hibernate.org/). I understand CF9 is going to have full support for Hibernate and I wonder what, if any, impact this might have on projects such as DataFaucet or Transfer. Just curious.
Anyway, thank you very much Isaac for your comments! Much appreciated.
Here's Mark's http://www.compoundtheory.com/?action=displayPost&...
And here are my biases :) http://datafaucet.riaforge.org/blog/index.cfm/2008...
Re: "giving up SQL": Y'know, there are a lot of ColdFusion programmers who've made those sorts of comments about using an ORM system. I actually just finished up an article for the next FAQU that talks about some of the theory behind ORM and gives some fairly general information about the various ORMs that are available. Truth is using an ORM really wouldn't take SQL away from you if you didn't want it to.
Something I didn't realize until Mark fact-checked the article is that Transfer has some custom tags for executing TQL that make it nearly identical to standard cfquery tags. TQL in the current version only works for select statements (no insert/update/delete), but it's on the roadmap and you can always get the datasource bean and use that to execute some standard cfquery tags if there's something you find difficult or unavailable with the Transfer features.
It's a similar story as far as I know for Reactor although the feature set and the syntax are fairly different.
Beyond that FourQ and DataFaucet both started out actually as attempts to abstract the SQL language on a lower level. So with DataFaucet you should be able to do most anything you can do with standard SQL, including joins, aggregates, concatenation and unions. I've strived to make the syntax for it intuitive from the perspective of someone who knows SQL, so ideally you should be able to look at some DF syntax and have a pretty good idea right away what it's doing -- ideally you'll see the SQL in your head, although you can also use statement.getSyntax() to actually return the SQL.
DataMgr isn't technically an ORM, but same sort of deal.
Thanks again for pointing me towards more useful info! Both Mark and yourself make valid points regarding CF9+Hibernate.
Besides, Hibernate would be another animal for us CFers to learn if we're not already familiar with it. And from what I've seen so far, DataFaucet appears to be a fairly easy syntax to pick up and use. Again, I really need to take time to learn more about ORMs, and more specifically DataFaucet. ORMs definitely appear to be able to shorten development time _and_ lines of code.
So we do get ideas from each other, though the syntax for doing things varies a lot from one to the next. And if it's syntax you're going to be using regularly, you want to make it something that you find logical to follow so you can spend your time working on your business model and not so much on trying to figure out your ORM tools. :)
Even in the FAQU article that's coming up I pointed out that where there's a small learning curve for DataFaucet, the learning curve for Transfer's TQL custom tags is almost nothing for someone familiar with CFML. So I'll readily admit when I see advantages to using someone else's tools. :)